Review
| Copyright © Microsoft Corporation. This document is an archived reproduction of a version originally published by Microsoft. It may have slight formatting modifications for consistency and to improve readability. |

| Understanding Interface Definition Language: A Developer's Survival Guide |
| IDL is the preferred way to describe your interfaces. However, many developers only have a rudimentary knowledge of IDL. Knowing IDL will help you think about your interfaces in a more explicit manner, which is especially useful now that you spend so much time exposing interfaces. |
| This article assumes you're familiar with C++, COM, and marshaling. |
|
Bill Hludzinski is a software developer at Vivisoft Corporation (http://www.vivisoft.com) and can be reached at billh@vivisoft.com.
|
|
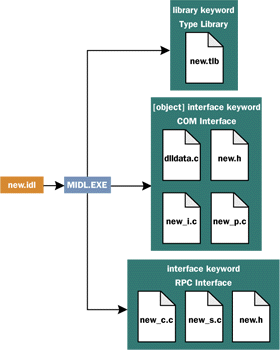
The age of IDL
(Interface Definition Language) is upon us. IDL is the
preferred way to describe your interfaces. However, many developers
only have a rudimentary knowledge of IDL. They rely on the Visual C++
wizards to generate their IDL files, but don't have any idea what the
code does. On the other hand, who wants to browse the MIDL Programmer's Guide
in their spare time, trying to learn a new language with over 140
keywords? To meet your IDL needs, I am going to provide a basic survival
guide that will show you what IDL is, when you need it, and the basics
of using it. You'll find that knowing IDL will help you think about
your interfaces in a more explicit manner, which is especially useful
now that you spend so much of your time exposing interfaces.
Review |
 |
|
Just Like C++! |
long AddValues(long val1,
long val2);
|
| the corresponding IDL file would look like this: |
long AddValues([in] long val1, [in] long val2); |
| So
IDL is rooted in the data type declaration portion
of C and C++. It supports all of the standard C++ data
types as well as the data definition keywords that you've grown to know
and love. More importantly, IDL's data types and definitions are both
language-neutral and
platform-neutral.
Code Generation |
cpp_quote("#define UNICODE")
|
| would appear in the generated code like this: |
#define UNICODE |
| Much of the time your IDL file will need to see data type definitions from other header files and even other IDL or ODL files to process base data types. In these cases, you will have to use the import directive, which actually includes the file in the MIDL processing. The include directive just makes files available to the source code from which the proxy/stub code is compiled. It's important to remember that any function declarations in imported files are ignored, and that in the resulting source code, the generated header file will not directly contain the imported types. Instead an #include directive is generated for the header corresponding to the imported interface. The following import statement |
import "moose.idl" |
| would be generated in the source code as: |
#include "moose.h" |
| Since
I'm discussing the importing of files, it's probably a good time to
mention the standard IDL include files. wtypes.idl, unknwn.idl,
objidl.idl, and oaidl.idl ship with Visual C++ and Visual J++. You can
find them in their respective include directories. These files document
the standard C library of the COM era in one place. They include the
data types, #defines, and interfaces that have been defined (and in many
cases implemented) by Microsoft for supporting COM.
Your First Attributes |
void fx([in] long l1, [out] long *pl2,
[in, out] long *pl3);
|
| In
this case, the attributes are all applied to the arguments of this
function. However, attributes are not limited to arguments alone. They
can be applied to other things such as functions or libraries. [in] and
[out] are two of the fundamental attributes that IDL makes available.
|
long fx([in] const long *pval); |
| If a client called this function, passing the address of a variable whose value was 17, the value 17 would be sent across the network from the client's proxy to the server's stub. On the server, the stub code would copy the value 17 into the server's address space and call the server function with a pointer that pointed to that value (see Figure 4). |
 |
|
|
// pval cannot be null long fx([in, ref] const long *pval); |
| Pointers that can be null are called unique pointers and are indicated by the [unique] attribute. |
// pval can be null long fx([in, unique] const long *pval); |
long fx([in] long *pval1, [in] long *pval2); |
| Now consider the following client code: |
long l1 = 10; long l2 = fx(&l1, &l1); |
| This
code is noteworthy because it passes the same pointer twice in the same
function invocation. This means that the value pointed to by both
pointers will be passed across the network twice, once for each value.
When the stub unmarshals the parameters on the server side, it will
allocate two distinct memory blocks, one for each value, and set each
pointer to point to its value's newly allocated memory. So on the server
side, even though both pointers will point to memory with a value of
10, they will be pointing to different memory locations, unlike on the
client side.
|
long fx([in, full] long *pval1,
[in, full] long *pval2);
|
typedef struct tagELEMENT {
long lValue;
[unique] struct tagELEMENT *pPrev;
[unique] struct tagELEMENT *pNext;
} ELEMENT;
void GetElementList([out] ELEMENT *pList);
|
| This
example contains pointers within a user-defined
structure. These types of pointers are embedded pointers, whereas your
typical pointer (which isn't embedded in a structure) is a top-level
pointer. Let's say that the purpose of this function is to return a
doubly linked list of elements to the caller.
|
void *CoTaskMemAlloc(ULONG cb); void *CoTaskMemRealloc(void *pv, ULONG cb); void CoTaskMemFree(void *pv); |
| When
you're working with embedded pointers and linked user-defined types,
you will be using callee-allocated memory, and these functions will
help. Further discussion of the COM task allocator is beyond the scope
of this article, but if you'd like to see it explained and put into use,
refer
to Don Box's OLE Q&A column in the October 1995 issue
of MSJ.
Strings and Arrays |
void MyFunction([in,
string] const OLECHAR
*pwszName);
|
void Fx([in] long alValues[4]); |
| This example passes a fixed array of four longs with which the marshaler can easily figure out how much data to copy to the server process. However, the most common case is where the size of the array will not be known until runtime. In this situation, IDL provides a series of attributes for specifying the array's size at compile time or runtime. These types of arrays are called conformant arrays, and the size of the array may be defined via the [size_is] attribute. Typically, you will use one of the other arguments in a function to specify the array size using [size_is]. |
void Fx([in] long cItems,
[in, size_is(cItems)] short aItems[]);
|
void Fx([in] long cMax,
[in, out] long *pcUsed,
[in,out,size_is(cMax),
length_is(*pcUsed)] long *aValues);
|
| On
the way in, the [size_is] attribute lets the marshaler know that the
array is cMax longs so the stub will allocate the required memory on
the server. But the [length_is] attribute tells the marshaler that only
*pcUsed longs need to be marshaled, so they are the only elements of the
array that are actually transmitted to the server. Quite efficient!
|
void Fx([in, size_is(100), first_is(12),
last_is(22)] long *aValues);
|
| For another look at strings and arrays in IDL, check out Don Box's November 1996
ActiveX/COM column. He covers the techniques in greater detail, as well
as multidimensional arrays and performance comparisons between the
different array-passing techniques.
Type Libraries |
[uuid(54674299-3A82-101B-8181-00AA003743D3)] library MyLib
{
typedef enum {
btError = 0x0010,
btQuestion = 0x0020,
btWarning = 0x0030,
btInformation = 0x0040
} BeepTypes;
[dllname("USER32")]
module MyUser32
{
[entry("MessageBeep"),
helpstring(
"Makes the sound
specified by btSound")]
long _stdcall
MessageBeep(BeepTypes
btSound);
};
};
|
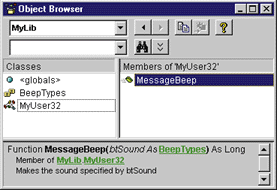
| I've defined a type library called MyLib, which contains an enumeration definition and a DLL interface. The DLL's file name is USER32.DLL, but I am calling the module MyUser32. This module has one entry point: the MessageBeep function. Note that the typedef is within the library statement's braces, but not the module. You can compile it into a type library by running MIDL with the following command line: |
midl user.idl |
 |
|
|
Private Sub Command1_Click()
Dim Sound As BeepTypes
Sound = btQuestion
MessageBeep (Sound)
End Sub
|
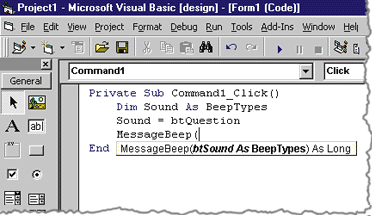
| As you type in the code, you will notice that Auto List Members has picked up your type information and can offer you choices for the enumeration values (see Figure 8). When you type in the function call, you will see that Auto Quick Info lists all of the data types and data members for you (see Figure 9). |
 |
 |
|
|
long _stdcall MessageBeep(int iVolume,
BeepTypes btSound);
|
| the Visual Basic code could make the call with the parameters out of order: |
Private Sub Command1_Click()
MessageBeep (btSound:=btQuestion, iVolume:=100)
End Sub
|
Interfaces |
[uuid(348ACF20-C9B9-11d1-ABE5-966A46661731)]
interface MyRPCInterface
{
void Fx(int iValue);
}
|
[object, uuid(348ACF20-C9B9-11d1-ABE5-966A46661731)]
interface IDerivedInterface : IUnknown
{
import "unknwn.idl";
import "wtypes.idl";
HRESULT Fx(int iValue);
}
|
typedef interface IStorage *LPSTORAGE; |
| You can even pass interface pointers as function parameters: |
HRESULT StoreData([in] IStorage *pstg); |
| However, sometimes you will not know the interface type at design time, so IDL provides support for dynamically typed interfaces with the [iid_is] parameter attribute: |
HRESULT CreateInstance([in] REFIID riid,
[out, iid_is(riid)] void **ppv);
|
| In the code that called this method, the riid parameter would take the IID of the dynamically typed parameter: |
CreateInstance(IID_Car, &ICar); |
|
Coclasses
|
[uuid(0D248C00-CA6D-11d1-ABE5-8DDA2C299A21)] library MyLib2
{
[object,
uuid(0D248C01-CA6D-11d1-ABE5-8DDA2C299A21)]
interface IDerivedInterface : IUnknown
{
import "unknwn.idl";
import "wtypes.idl";
HRESULT Fx(int iValue);
};
[uuid(CE395E80-CA6C-11d1-ABE5-8DDA2C299A21)]
coclass Drone {
interface IDerivedInterface;
};
};
|
[uuid(CE395E80-CA6C-11d1-ABE5-8DDA2C299A21)]
coclass Drone {
[source] dispinterface IDerivedInterface;
};
|
|
Dispatch Interfaces
|
importlib(stdole32.tlb)
[uuid(348ACF20-C9B9-11d1-ABE5-966A46661731)]
dispinterface DFlyingSaucer
{
properties:
[id(1)] long Altitude;
[id(2)] long Speed;
methods:
[id(3)] HRESULT Land([in] long lDirection);
[id(4)] HRESULT TakeOff();
}
|
| A
much more important difference is that a dispinterface doesn't have a
vtable. All dispinterface methods and properties are accessed using an
index with Invoke.
|
importlib(stdole32.tlb)
[object, dual,
uuid(348ACF20-C9B9-11d1-ABE5-966A46661731)]
interface DIFlyingSaucer : IDispatch
{
[id(1), propget] HRESULT Altitude(long);
[id(1), propput] HRESULT Altitude(long);
[id(2), propget] HRESULT Speed(long);
[id(2), propput] HRESULT Speed(long);
[id(3)] HRESULT Land([in] long lDirection);
[id(4)] HRESULT TakeOff();
}
|
| Note
the naming convention; dispatch interfaces have a D prefix, dual
interfaces have a DI prefix, and regular interfaces have an I prefix.
Conclusion From the August 1998 issue of Microsoft Systems Journal. |